Software Engineering Part 1
- Python Method vs Function.
- Magic Methods
- Further important OOPs reading
Here is a list of resources for advanced Python object-oriented programming topics.
- class methods, instance methods, and static methods – these are different types of methods that can be accessed at the class or object level
- class attributes vs instance attributes – you can also define attributes at the class level or at the instance level
- multiple inheritance, mixins – A class can inherit from multiple parent classes
- Python decorators – Decorators are a short-hand way for using functions inside other functions
Useful links:
- Code examples: https://github.com/udacity/DSND_Term2/tree/master/lessons
Virtual Environments
Python Environments
In the next part of the lesson, you’ll be given a workspace where you can upload files into a Python package and pip install the package. If you decide to install your package on your local computer, you’ll want to create a virtual environment. A virtual environment is a silo-ed Python installation apart from your main Python installation. That way you can install packages and delete the virtual environment without affecting your main Python installation
Let’s talk about two different Python environment managers: conda and venv. You can create virtual environments with either one. Below you’ll read about each of these environment managers including some advantages and disadvantages. If you’ve taken other data science, machine learning or artificial intelligence courses at Udacity, you’re probably already familiar with conda.
Conda
Conda does two things: manages packages and manages environments.
As a package manager, conda makes it easy to install Python packages especially for data science. For instance, typing conda install numpy will install the numpy package.
As an environment manager, conda allows you to create silo-ed Python installations. With an environment manager, you can install packages on your computer without affecting your main Python installation.
The command line code looks something like this:
conda create --name environmentname
source activate environmentname
conda install numpy
Pip and Venv
There are other environmental managers and package managers besides conda. For example, venv is an environment manager that comes pre-installed with Python 3. Pip is a package manager.
Pip can only manage Python packages whereas conda is a language agnostic package manager. In fact, conda was invented because pip could not handle data science packages that depended on libraries outside of Python. If you look at the history of conda, you’ll find that the software engineers behind conda needed a way to manage data science packages (NumPy, Matplotlib, etc.) that relied on libraries outside of Python.
Conda manages environments AND packages. Pip only manages packages.
To use venv and pip, the commands look something like this:
python3 -m venv environmentname
source environmentname/bin/activate
pip install numpy
Which to Choose
Whether you choose to create environments with venv or conda will depend on your use case. Conda is very helpful for data science projects, but conda can make generic Python software development a bit more confusing; that’s the case for this project.
If you create a conda environment, activate the environment, and then pip install the distributions package, you’ll find that the system installs your package globally rather than in your local conda environment. However, if you create the conda environment and install pip simultaneously, you’ll find that pip behaves as expected installing packages into your local environment:
conda create --name environmentname pip
On the other hand, using pip with venv works as expected. Pip and venv tend to be used for generic software development projects including web development. For this lesson on creating packages, you can use conda or venv if you want to develop locally on your computer and install your package.
Contributing to a GitHub project
Here are a few links about how to contribute to a github project:
Advanced Python OOP Topics
Here are a few links to more advanced OOP topics that appear in the Scikit-learn package:
Putting Code on PyPi
PyPi vs. Test PyPi
Note that pypi.org and test.pypy.org are two different websites. You’ll need to register separately at each website. If you only register at pypi.org, you will not be able to upload to the test.pypy.org repository.
Also, remember that your package name must be unique. If you use a package name that is already taken, you will get an error when trying to upload the package.
Summary of the Terminal Commands Used in the Video
cd binomial_package_files
python setup.py sdist
pip install twine
# commands to upload to the pypi test repository
twine upload --repository-url https://test.pypi.org/legacy/ dist/*
pip install --index-url https://test.pypi.org/simple/ dsnd-probability
# command to upload to the pypi repository
twine upload dist/*
pip install dsnd-probability
More PyPi Resources
Tutorial on distributing packages
This link has a good tutorial on distributing Python packages including more configuration options for your setup.py file: tutorial on distributing packages. You’ll notice that the python command to run the setup.py is slightly different with
python3 setup.py sdist bdist_wheel
This command will still output a folder called dist. The difference is that you will get both a .tar.gz file and a .whl file. The .tar.gz file is called a source archive whereas the .whl file is a built distribution. The .whl file is a newer type of installation file for Python packages. When you pip install a package, pip will first look for a whl file (wheel file) and if there isn’t one, will then look for the tar.gz file.
A tar.gz file, ie an sdist, contains the files needed to compile and install a Python package. A whl file, ie a built distribution, only needs to be copied to the proper place for installation. Behind the scenes, pip installing a whl file has fewer steps than a tar.gz file.
Other than this command, the rest of the steps for uploading to PyPi are the same.
Other Links
If you’d like to learn more about PyPi, here are a couple of resources:
Building a portfolio
https://learnpython.com/blog/11-tips-for-building-a-strong-data-science-portfolio-with-python/
For a much more detailed explanation of distributing Python packages, check out the documentation on Distutils.
Machine Learning in production
Lesson 1 – Introduction to Deployment
Specifically in this lesson, we will look at answering the following questions:
- What’s the machine learning workflow?
- How does deployment fit into the machine learning workflow?
- What is cloud computing?
- Why would we use cloud computing for deploying machine learning models?
- Why isn’t deployment a part of many machine learning curriculums?
- What does it mean for a model to be deployed?
- What are the essential characteristics associated with the code of deployed models?
- What are different cloud computing platforms we might use to deploy our machine learning models?
What is cloud computing and why would you use it?
Cloud Computing
In this section, we will focus on answering two questions:
- What is cloud computing?
- Why would a business decide to use cloud computing?
This section will be a high-level look. However, you can dive more into the details by looking at the optional pages added at the end of this section.
What is cloud computing?
You can think of cloud computing as transforming an IT product into an IT service.
Consider the following example:
Have you ever had to backup and store important files on your computer? Maybe these files are family photos from your last vacation. You might store these photos on a flash drive. These days you have an alternative option to store these photos in the cloud using a cloud storage provider, like: Google Drive, Apple’s iCloud, or Microsoft’s OneDrive.
Cloud computing can simply be thought of as transforming an Information Technology (IT) product into a service. With our vacation photos example, we transformed storing photos on an IT product, the flash drive; into storing them using a service, like Google Drive.
Using a cloud storage service provides the benefits of making it easier to access and share your vacation photos, because you no longer need the flash drive. You’ll only need a device with an internet connection to access your photos and to grant permission to others to access your photos.
Generally, think of cloud computing as using an internet connected device to log into a cloud computing service, like Google Drive, to access an IT resource, your vacation photos. These IT resources, your vacation photos, are stored in the cloud provider’s data center. Besides cloud storage, other cloud services include: cloud applications, databases, virtual machines, and other services like SageMaker.
Why would a business decide to use cloud computing?
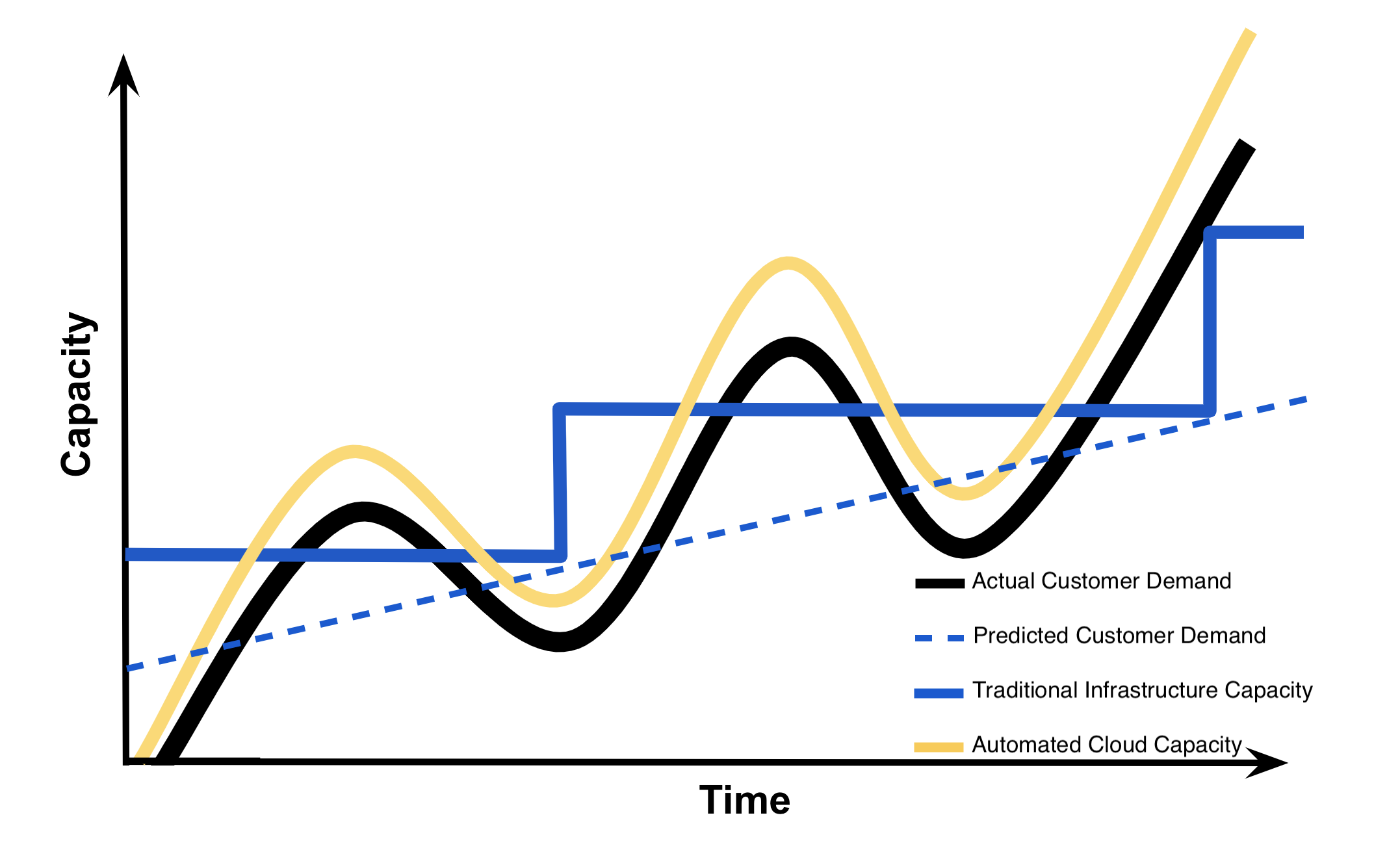
Most of the factors related to choosing cloud computing services, instead of developing on-premise IT resources are related to time and cost. The capacity utilization graph below shows how cloud computing compares to traditional infrastructure (on-premise IT resources) in meeting customer demand.
Capacity in the graph below can be thought of as the IT resources like: compute capacity, storage, and networking, that’s needed to meet customer demand for a business’ products and the costs associated with those IT resources. In our vacation photos example, customer demand is for storing and sharing customer photos. The IT resources are the required software and hardware that enables photo storage and sharing in the cloud or on-premise (traditional infrastructure).
Looking at the graph, notice that traditional infrastructure doesn’t scale when there are spikes in demand, and also leaves excess when preparing for future demand. This ability to easily meet unstable, fluctuating customer demand illustrates many of the benefits of cloud computing.
Summary of Benefits of Risks Associated with Cloud Computing
The capacity utilization graph above was initially used by cloud providers like Amazon to illustrate the benefits of cloud computing. Summarized below are the benefits of cloud computing that are often what drives businesses to include cloud services in their IT infrastructure [1]. These same benefits are echoed in those provided by cloud providers Amazon (benefits), Google (benefits), and Microsoft (benefits).
Benefits
- Reduced Investments and Proportional Costs (providing cost reduction)
- Increased Scalability (providing simplified capacity planning)
- Increased Availability and Reliability (providing organizational agility)
Below we have also summarized he risks associated with cloud computing [1]. Cloud providers don’t typically highlight the risks assumed when using their cloud services like they do with the benefits, but cloud providers like: Amazon (security), Google (security), and Microsoft (security) often provide details on security of their cloud services. It’s up to the cloud user to understand the compliance and legal issues associated with housing data within a cloud provider’s data center instead of on-premise. The service level agreements (SLA) provided for a cloud service often highlight security responsibilities of the cloud provider and those assumed by the cloud user.
Risks
- (Potential) Increase in Security Vulnerabilities
- Reduced Operational Governance Control (over cloud resources)
- Limited Portability Between Cloud Providers
- Multi-regional Compliance and Legal Issues
References
1. Erl, T., Mahmood, Z., & Puttini R,. (2013). Cloud Computing: Concepts, Technology, & Architecture. Upper Saddle River, NJ: Prentice Hall.Chapter 3: Understanding Cloud Computing provides an outline of the business drivers, benefits and risks of cloud computing.
Additional Resources
For the purpose of deploying machine learning models, it’s important to understand the basics of cloud computing. The essentials are provided above, but if you want to learn more about the overall role of cloud computing in developing software, check out the [Optional] Cloud Computing Defined and [Optional] Cloud Computing Explained sections at the end of this lesson along with the additional resources provided below.
- National Institute of Standards and Technology formal definition of Cloud Computing.
- Kavis, M. (2014). Architecting the Cloud: Design Decisions for Cloud Computing Service Models. Hoboken, NJ: Wiley. Chapter 3 provides the worst practices of cloud computing which highlights both risks and benefits of cloud computing. Chapter 9 provides the security responsibilities by service model.
- Amazon Web Services (AWS) discusses their definition of Cloud Computing.
- Google Cloud Platform (GCP) discusses their definition of Cloud Computing.
- Microsoft Azure (Azure) discusses their definition of Cloud Computing.
Paths to deployment (Very good to read)
Deployment to Production
Recall that:
Deployment to production can simply be thought of as a method that integrates a machine learning model into an existing production environment so that the model can be used to make decisions or predictions based upon data input into the model.
This means that moving from modeling to deployment, a model needs to be provided to those responsible for deployment. We are going to assume that the machine learning model we will be deploying was developed in Python.
Paths to Deployment
There are three primary methods used to transfer a model from the modeling component to the deployment component of the machine learning workflow. We will be discussing them in order of least to most commonly used. The third method that’s most similar to what’s used for deployment within Amazon’s SageMaker.
Paths to Deployment:
- Python model is recoded into the programming language of the production environment.
- Model is coded in Predictive Model Markup Language (PMML) or Portable Format Analytics (PFA).
- Python model is converted into a format that can be used in the production environment.
Recoding Model into Programming Language of Production Environment
The first method which involves recoding the Python model into the language of the production environment, often Java or C++. This method is rarely used anymore because it takes time to recode, test, and validate the model that provides the same predictions as the original.
Model is Coded in PMML or PFA
The second method is to code the model in Predictive Model Markup Language (PMML) or Portable Format for Analytics (PFA), which are two complementary standards that simplify moving predictive models to deployment into a production environment. The Data Mining Group developed both PMML and PFA to provide vendor-neutral executable model specifications for certain predictive models used by data mining and machine learning. Certain analytic software allows for the direct import of PMML including but not limited to IBM SPSS, R, SAS Base & Enterprise Miner, Apache Spark, Teradata Warehouse Miner, and TIBCO Spotfire.
Model is Converted into Format that’s used in the Production Environment
The third method is to build a Python model and use libraries and methods that convert the model into code that can be used in the production environment. Specifically most popular machine learning software frameworks, like PyTorch, TensorFlow, SciKit-Learn, have methods that will convert Python models into intermediate standard format, like ONNX (Open Neural Network Exchange format). This intermediate standard format then can be converted into the software native to the production environment.
- This is the easiest and fastest way to move a Python model from modeling directly to deployment.
- Moving forward this is typically the way models are moved into the production environment.
- Technologies like containers, endpoints, and APIs (Application Programming Interfaces) also help ease the work required for deploying a model into the production environment.
We will discuss these technologies in more detail in the next sections.
Machine Learning Workflow and DevOps
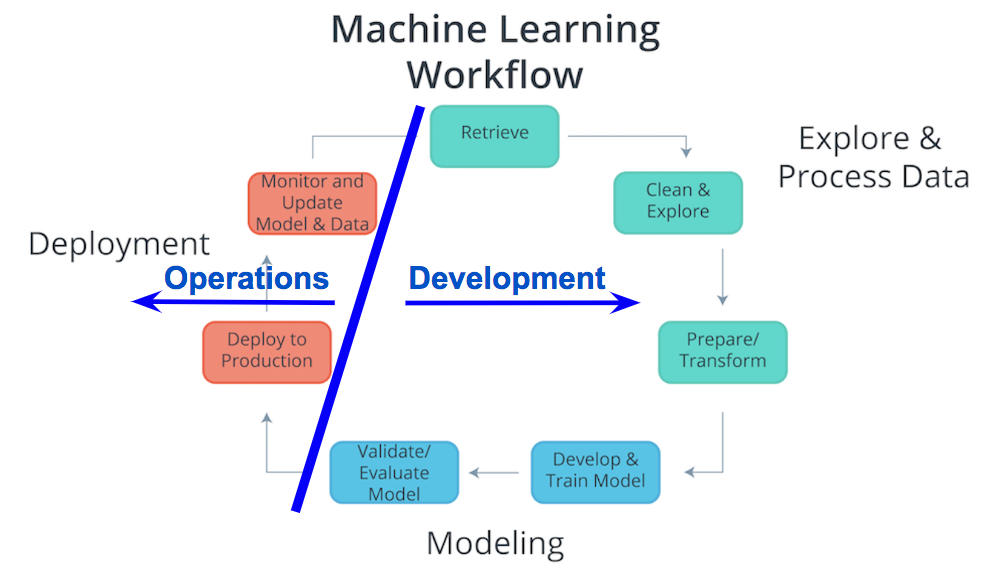
Machine Learning Workflow and Deployment
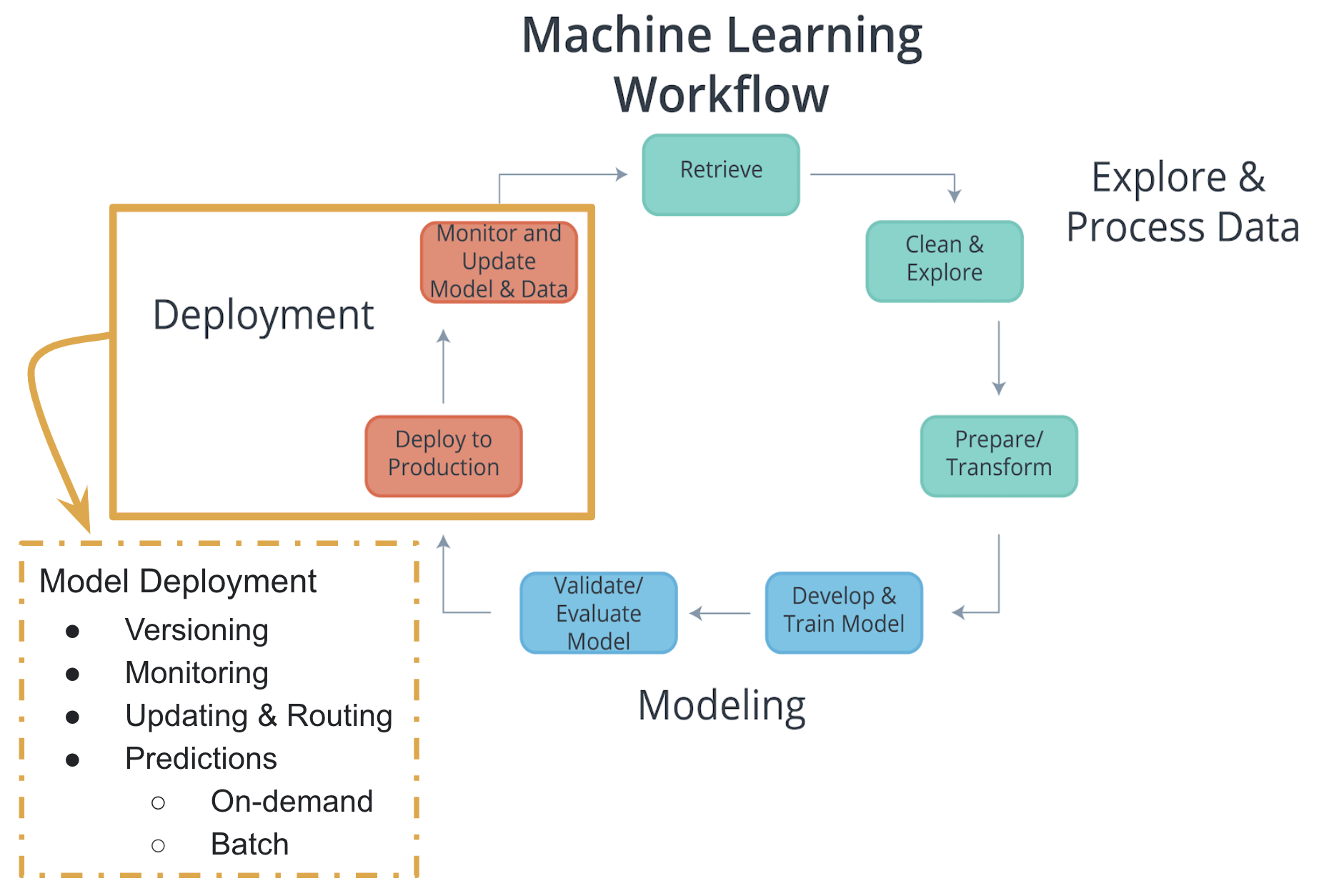
Considering the components of the Machine Learning Workflow, one can see how Exploring and Processing Data is tightly coupled with Modeling. The modeling can’t occur without first having the data the model will be based upon prepared for the modeling process.
Comparatively deployment is more tightly coupled with the production environment than with modeling or exploring and processing the data. Therefore, traditionally there’s was a separation between Deployment and the other components of the machine learning workflow. Specifically looking at the diagram above, the Process Data and Modeling are considered Development; whereas, Deployment is typically considered Operations.
In the past typically, development was handled by analysts; whereas, operations was handled by software developers responsible for the production environment. With recent developments in technology (containers, endpoints, APIs) and the most common path of deployment; this division between development and operations softens. The softening of this division enables analysts to handle certain aspects of deployment and enables faster updates to faltering models.
Deployment within Machine Learning Curriculum
Deployment is not commonly included in machine learning curriculum. This likely is associated with the analyst’s typical focus on Exploring and Processing Data and Modeling, and the software developer’s focusing more on Deployment and the production environment. Advances in cloud services, like SageMaker and ML Engine, and deployment technologies, like Containers and REST APIs, allow for analysts to easily take on the responsibilities of deployment.
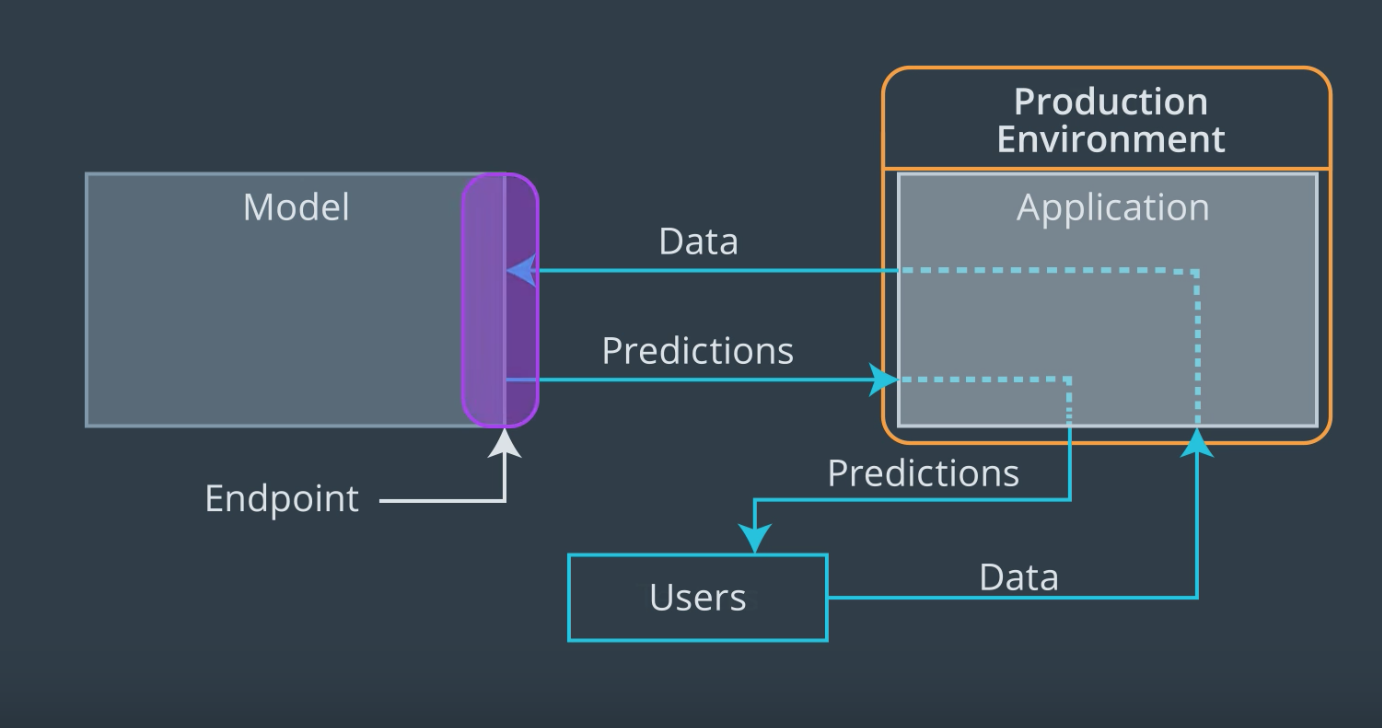
Production Environment and the Endpoint
When we discussed the production environment, the endpoint was defined as the interface to the model. This interface (endpoint) facilitates an ease of communication between the model and the application. Specifically, this interface (endpoint)
- Allows the application to send user data to the model and
- Receives predictions back from the model based upon that user data.
Model, Application, and Endpoint

One way to think of the endpoint that acts as this interface, is to think of a Python program where:
- the endpoint itself is like a function call
- the function itself would be the model and
- the Python program is the application.
The image above depicts the association between a Python program and the endpoint, model, and application.
- the endpoint: line 8 function call to ml_model
- the model: beginning on line 14 function definition for ml_model
- the application: Python program web_app.py

Using this example above notice the following:
- Similar to a function call the endpoint accepts user data as the input and returns the model’s prediction based upon this input through the endpoint.
- In the example, the user data is the input argument and the prediction is the returned value from the function call.
- The application, here the python program, displays the model’s prediction to the application user.
This example highlights how the endpoint itself is just the interface between the model and the application; where this interface enables users to get predictions from the deployed model based on their user data.
Next we’ll focus on how the endpoint (interface) facilitates communication between application and model.
Endpoint and REST API
Communication between the application and the model is done through the endpoint (interface), where the endpoint is an Application Programming Interface (API).
- An easy way to think of an API, is as a set of rules that enable programs, here the application and the model, to communicate with each other.
- In this case, our API uses a REpresentational State Transfer, REST, architecture that provides a framework for the set of rules and constraints that must be adhered to for communication between programs.
- This REST API is one that uses HTTP requests and responses to enable communication between the application and the model through the endpoint (interface).
- Noting that both the HTTP request and HTTP response are communications sent between the application and model.
The HTTP request that’s sent from your application to your model is composed of four parts:
- Endpoint
- This endpoint will be in the form of a URL, Uniform Resource Locator, which is commonly known as a web address.
- HTTP Method
- Below you will find four of the HTTP methods, but for purposes of deployment our application will use the POST method only.
- HTTP Headers
- The headers will contain additional information, like the format of the data within the message, that’s passed to the receiving program.
- Message (Data or Body)
- The final part is the message (data or body); for deployment will contain the user’s data which is input into the model.
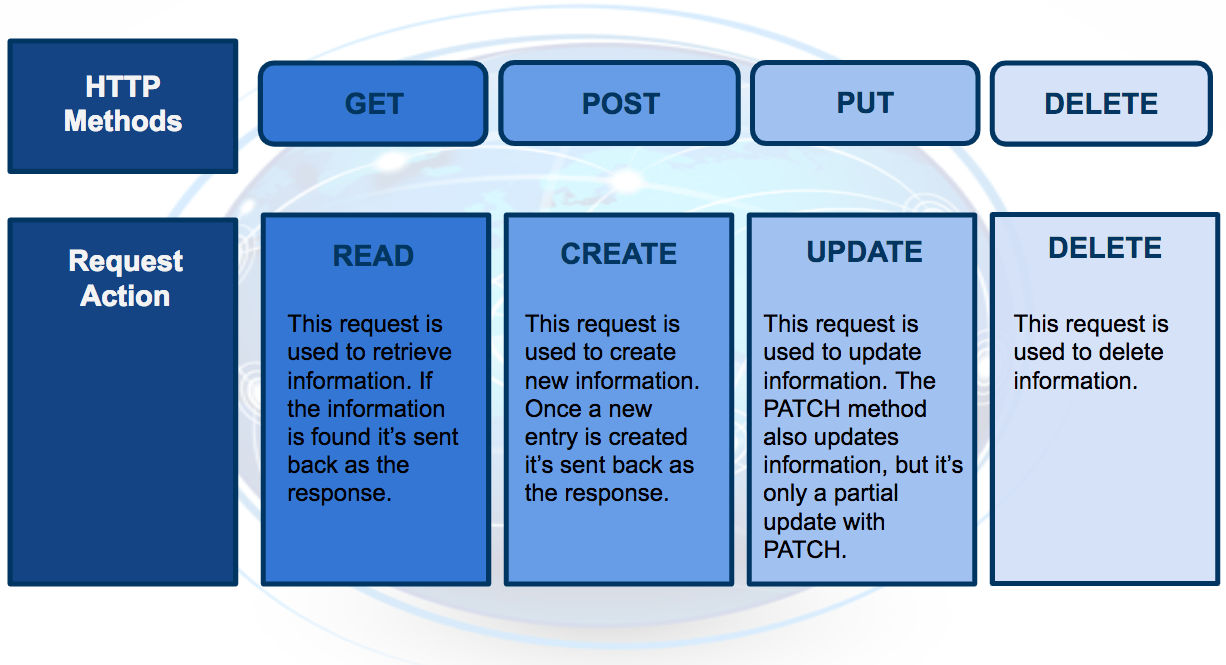
The HTTP response sent from your model to your application is composed of three parts:
- HTTP Status Code
- If the model successfully received and processed the user’s data that was sent in the message, the status code should start with a 2, like 200.
- HTTP Headers
- The headers will contain additional information, like the format of the data within the message, that’s passed to the receiving program.
- Message (Data or Body)
- What’s returned as the data within the message is the prediction that’s provided by the model.
This prediction is then presented to the application user through the application. The endpoint is the interface that enables communication between the application and the model using a REST API.
As we learn more about RESTful API, realize that it’s the application’s responsibility:
- To format the user’s data in a way that can be easily put into the HTTP request message and used by the model.
- To translate the predictions from the HTTP response message in a way that’s easy for the application user’s to understand.
Notice the following regarding the information included in the HTTP messages sent between application and model:
- Often user’s data will need to be in a CSV or JSON format with a specific ordering of the data that’s dependent upon the model used.
- Often predictions will be returned in CSV or JSON format with a specific ordering of the returned predictions dependent upon the model used.
Containers

Model, Application, and Containers
When we discussed the production environment, it was composed of two primary programs, the model and the application, that communicate with each other through the endpoint (interface).
- The model is simply the Python model that’s created, trained, and evaluated in the Modeling component of the machine learning workflow.
- The application is simply a web or software application that enables the application users to use the model to retrieve predictions.
Both the model and the application require a computing environment so that they can be run and available for use. One way to create and maintain these computing environments is through the use of containers.
- Specifically, the model and the application can each be run in a container computing environment. The containers are created using a script that contains instructions on which software packages, libraries, and other computing attributes are needed in order to run a software application, in our case either the model or the application.
Containers Defined
- A container can be thought of as a standardized collection/bundle of software that is to be used for the specific purpose of running an application.
As stated above container technology is used to create the model and application computational environments associated with deployment in machine learning. A common container software is Docker. Due to its popularity sometimes Docker is used synonymously with containers.
Containers Explained
Often to first explain the concept of containers, people tend to use the analogy of how Docker containers are similar to shipping containers.
- Shipping containers can contain a wide variety of products, from food to computers to cars.
- The structure of a shipping container provides the ability for it to hold different types of products while making it easy to track, load, unload, and transport products worldwide within a shipping container.
Similarly Docker containers:
- Can contain all types of different software.
- The structure of a Docker container enables the container to be created, saved, used, and deleted through a set of common tools.
- The common tool set works with any container regardless of the software the container contains.
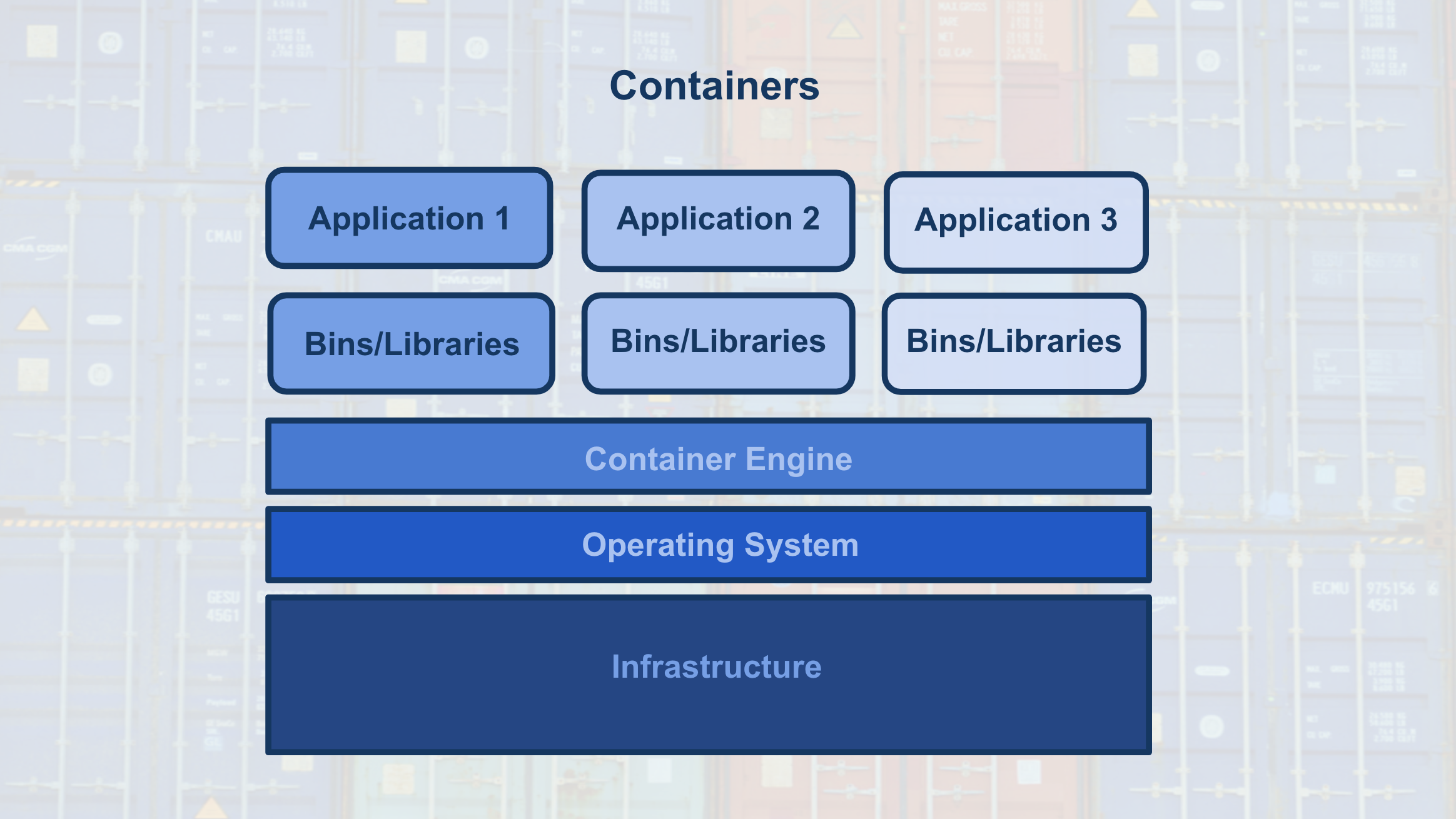
Container Structure
The image below shows the basic structure of a container, you have:
- The underlying computational infrastructure which can be: a cloud provider’s data center, an on-premise data center, or even someone’s local computer.
- Next, you have an operating system running on this computational infrastructure, this could be the operating system on your local computer.
- Next, there’s the container engine, this could be Docker software running on your local computer. The container engine software enables one to create, save, use, and delete containers; for our example, it could be Docker running on a local computer.
- The final two layers make up the composition of the containers.
- The first layer of the container is the libraries and binaries required to launch, run, and maintain the next layer, the application layer.
- The image below shows three containers running three different applications.
This architecture of containers provides the following advantages:
- Isolates the application, which increases security.
- Requires only software needed to run the application, which uses computational resources more efficiently and allows for faster application deployment.
- Makes application creation, replication, deletion, and maintenance easier and the same across all applications that are deployed using containers.
- Provides a more simple and secure way to replicate, save, and share containers.
As indicated by the fourth advantage of using containers, a container script file is used to create a container.
- This text script file can easily be shared with others and provides a simple method to replicate a particular container.
- This container script is simply the instructions (algorithm) that is used to create a container; for Docker these container scripts are referred to as dockerfiles.
This is shown with the image below, where the container engine uses a container script to create a container for an application to run within. These container script files can be stored in repositories, which provide a simple means to share and replicate containers. For Docker, the Docker Hub is the official repository for storing and sharing dockerfiles. Here’s an example of a dockerfile that creates a docker container with Python 3.6 and PyTorch installed.

Characteristics of Deployment and Modeling
Recall that:
Deployment to production can simply be thought of as a method that integrates a machine learning model into an existing production environment so that the model can be used to make decisions or predictions based upon data input into this model.
Also remember that a production environment can be thought of as a web, mobile, or other software application that is currently being used by many people and must respond quickly to those users’ requests.
Keeping these things in mind, there are a number of characteristics of deployment and modeling that I’m going to introduce here. These concepts are introduced now to provide you with familiarity with these concepts for when you see them discussed in future lessons. Specifically, these concepts are provided as features that are made easier to use within cloud platforms services than if implemented with your own code.

Characteristics of Modeling
Hyperparameters
In machine learning, a hyperparameter is a parameter whose value cannot be estimated from the data.
- Specifically, a hyperparameter is not directly learned through the estimators; therefore, their value must be set by the model developer.
- This means that hyperparameter tuning for optimization is an important part of model training.
- Often cloud platform machine learning services provide methods that allow for automatic hyperparameter tuning for use with model training.
If the machine learning platform fails to offer an automatic hyperparameter option, one option is to use methods from scikit-learn Python library for hyperparameter tuning. Scikit-learn is a free machine learning Python library that includes methods that help with hyperparameter tuning.
Characteristics of Deployment
Model Versioning
One characteristic of deployment is the version of the model that is to be deployed.
- Besides saving the model version as a part of a model’s metadata in a database, the deployment platform should allow one to indicate a deployed model’s version.
This will make it easier to maintain, monitor, and update the deployed model.
Model Monitoring
Another characteristic of deployment is the ability to easily monitor your deployed models.
- Once a model is deployed you will want to make certain it continues to meet its performance metrics; otherwise, the application may need to be updated with a better performing model.
Model Updating and Routing
The ability to easily update your deployed model is another characteristic of deployment.
- If a deployed model is failing to meet its performance metrics, it’s likely you will need to update this model.
If there’s been a fundamental change in the data that’s being input into the model for predictions; you’ll want to collect this input data to be used to update the model.
- The deployment platform should support routing differing proportions of user requests to the deployed models; to allow comparison of performance between the deployed model variants.
Routing in this way allows for a test of a model performance as compared to other model variants.
Model Predictions
Another characteristic of deployment is the type of predictions provided by your deployed model. There are two common types of predictions:
- On-demand predictions
- Batch predictions
On-Demand Predictions
- On-demand predictions might also be called:
- online,
- real-time, or
- synchronous predictions
- With these type of predictions, one expects:
- a low latency of response to each prediction request,
- but allows for possibility high variability in request volume.
- Predictions are returned in the response from the request. Often these requests and responses are done through an API using JSON or XML formatted strings.
- Each prediction request from the user can contain one or many requests for predictions. Noting that many is limited based upon the size of the data sent as the request. Common cloud platforms on-demand prediction request size limits can range from 1.5(ML Engine) to 5 Megabytes (SageMaker).
On-demand predictions are commonly used to provide customers, users, or employees with real-time, online responses based upon a deployed model. Thinking back on our magic eight ball web application example, users of our web application would be making on-demand prediction requests.
Batch Predictions
- Batch predictions might also be called:
- asynchronous, or
- batch-based predictions.
- With these type of predictions, one expects:
- high volume of requests with more periodic submissions
- so latency won’t be an issue.
- Each batch request will point to specifically formatted data file of requests and will return the predictions to a file. Cloud services require these files will be stored in the cloud provider’s cloud.
- Cloud services typically have limits to how much data they can process with each batch request based upon limits they impose on the size of file you can store in their cloud storage service. For example, Amazon’s SageMaker limits batch predictions requests to the size limit they enforce on an object in their S3 storage service.
Batch predictions are commonly used to help make business decisions. For example, imagine a business uses a complex model to predict customer satisfaction across a number of their products and they need these estimates for a weekly report. This would require processing customer data through a batch prediction request on a weekly basis.
Machine Learning Cloud Platforms
There are a number of machine learning cloud platforms, we provide more details about a few below. In the next few lessons, you will learn how to use Amazon’s SageMaker to deploy machine learning models. Therefore, we focused on providing more information on Amazon’s SageMaker. To allow for a comparison of features offered by SageMaker, we also provide detailed information about Google’s ML Engine because it’s most similar to SageMaker.
Amazon Web Services (AWS)
Amazon Web Services (AWS) SageMaker is Amazon’s cloud service that allows you to build, train, and deploy machine learning models. Some advantages to using Amazon’s SageMaker service are the following:
- Flexibility in Machine Learning Software: SageMaker has the flexibility to enable the use of any programming language or software framework for building, training, and deploying machine learning models in AWS. For the details see the three methods of modeling within SageMaker below.
- Built-in Algorithms – There are at least fifteen built-in algorithms that are easily used within SageMaker. Specifically, built-in algorithms for discrete classification or quantitative analysis using linear learner or XGBoost, item recommendations using factorization machine, grouping based upon attributes using K-Means, an algorithm for image classification, and many other algorithms.
- Custom Algorithms – There are different programming languages and software frameworks that can be used to develop custom algorithms which include: PyTorch, TensorFlow, Apache MXNet, Apache Spark, and Chainer.
- Your Own Algorithms – Regardless of the programming language or software framework, you can use your own algorithm when it isn’t included within the built-in or custom algorithms above.
- Ability to Explore and Process Data within SageMaker: SageMaker enables the use of Jupyter Notebooks to explore and process data, along with creation, training, validation, testing, and deployment of machine learning models. This notebook interface makes data exploration and documentation easier.
- Flexibility in Modeling and Deployment: SageMaker provides a number of features and automated tools that make modeling and deployment easier. For the details on these features within SageMaker see below.
- Automatic Model Tuning: SageMaker provides a feature that allows hyperparameter tuning to find the best version of the model for built-in and custom algorithms. For built-in algorithms SageMaker also provides evaluation metrics to evaluate the performance of your models.
- Monitoring Models: SageMaker provides features that allow you to monitor your deployed models. Additionally with model deployment, one can choose how much traffic to route to each deployed model (model variant). More information on routing traffic to model variants can be found here and here .
- Type of Predictions: SageMaker by default allows for On-demand type of predictions where each prediction request can contain one to many requests. SageMaker also allows for Batch predictions, and request data size limits are based upon S3 object size limits.
Google Cloud Platform (GCP)
Google Cloud Platform (GCP) ML Engine is Google’s cloud service that allows you to build, train, and deploy machine learning models. Below we have highlighted some of the similarities and differences between these two cloud service platforms.
- Prediction Costs: The primary difference between the two is how they handle predictions. With SageMaker predictions, you must leave resources running to provide predictions. This enables less latency in providing predictions at the cost of paying for running idle services, if there are no (or few) prediction requests made while services are running. With ML Engine predictions, one has the option to not leave resources running which reduces cost associated with infrequent or periodic requests. Using this has more latency associated with predictions because the resources are in a offline state until they receive a prediction request. The increased latency is associated to bringing resources back online, but one only pays for the time the resources are in use. To see more about ML Engine pricing and SageMaker pricing.
- Ability to Explore and Process Data: Another difference between ML Engine and SageMaker is the fact that Jupyter Notebooks are not available within ML Engine. To use Jupyter Notebooks within Google’s Cloud Platform (GCP), one would use Datalab. GCP separates data exploration, processing, and transformation into other services. Specifically, Google’s Datalab can be used for data exploration and data processing, Dataprep can be used to explore and transform raw data into clean data for analysis and processing, and DataFlow can be used to deploy batch and streaming data processing pipelines. Noting that Amazon Web Services (AWS), also have data processing and transformation pipeline services like AWS Glue and AWS Data Pipeline.
- Machine Learning Software: The final difference is that Google’s ML Engine has less flexibility in available software frameworks for building, training, and deploying machine learning models in GCP as compared to Amazon’s SageMaker. For the details regarding the two available software frameworks for modeling within ML Engine see below.
- Google’s TensorFlow is an open source machine learning framework that was originally developed by the Google Brain team. TensorFlow can be used for creating, training, and deploying machine learning and deep learning models. Keras is a higher level API written in Python that runs on top of TensorFlow, that’s easier to use and allows for faster development. GCP provides both TensorFlow examples and a Keras example.
- Google’s Scikit-learn is an open source machine learning framework in Python that was originally developed as a Google Summer of Code project. Scikit-learn and an XGBoost Python package can be used together for creating, training, and deploying machine learning models. In the in Google’s example, XGBoost is used for modeling and Scikit-learn is used for processing the data.
- Flexibility in Modeling and Deployment: Google’s ML Engine provides a number of features and automated tools that make modeling and deployment easier, similar to the those provided by Amazon’s SageMaker. For the details on these features within ML Engine see below.
- Automatic Model Tuning: Google’s ML Engine provides a feature that enables hyperparameter tuning to find the best version of the model.
- Monitoring Models: Google’s ML Engine provides features that allow you to monitor your models. Additionally ML Engine provides methods that enable managing runtime versions and managing models and jobs.
- Type of Predictions: ML Engine allows for Online(or On-demand) type of predictions where each prediction request can contain one to many requests. ML Engine also allows for Batch predictions. More information about ML Engine’s Online and Batch predictions.
Microsoft Azure
Similar to Amazon’s SageMaker and Google’s ML Engine, Microsoft offers Azure AI. Azure AI offers an open and comprehensive platform that includes AI software frameworks like: TensorFlow, PyTorch, scikit-learn, MxNet, Chainer, Caffe2, and other software like their Azure Machine Learning Studio. For more details see Azure AI and Azure Machine Learning Studio.
Paperspace
Paperspace simply provides GPU-backed virtual machines with industry standard software tools and frameworks like: TensorFlow, Keras, Caffe, and Torch for machine learning, deep learning, and data science. Paperspace claims to provide more powerful and less expensive virtual machines than are offered by AWS, GCP, or Azure.
Cloud Foundry
Cloud Foundry is an open source cloud application platform that’s backed by companies like: Cisco, Google, IBM, Microsoft, SAP, and more. Cloud Foundry provides a faster and easier way to build, test, deploy, and scale applications by providing a choice of clouds, developer frameworks, and applications services to it’s users. Cloud Foundry Certified Platforms provide a way for an organization to have their cloud applications portable across platforms including IBM and SAP cloud platforms.
SageMaker Sessions & Execution Roles
SageMaker has some unique objects and terminology that will become more familiar over time. There are a few objects that you’ll see come up, over and over again:
- Session – A session is a special object that allows you to do things like manage data in S3 and create and train any machine learning models; you can read more about the functions that can be called on a session, at this documentation. The
upload_datafunction should be close to the top of the list! You’ll also see functions liketrain,tune, andcreate_modelall of which we’ll go over in more detail, later. - Role – Sometimes called the execution role, this is the IAM role that you created when you created your notebook instance. The role basically defines how data that your notebook uses/creates will be stored. You can even try printing out the role with
print(role)to see the details of this creation.
Uploading to an S3 Bucket
Another SageMaker detail that is new is the method of data storage. In these instances, we’ll be using S3 buckets for data storage.
S3 is a virtual storage solution that is mostly meant for data to be written to few times and read from many times. This is, in some sense, the main workhorse for data storage and transfer when using Amazon services. These are similar to file folders that contain data and metadata about that data, such as the data size, date of upload, author, and so on.
S3 stands for Simple Storage Service (S3).
After you upload data to a session, you should see that an S3 bucket is created, as indicated by an output like the following:
INFO: sagemaker: Created S3 bucket: <message specific to your locale, ex. sagemaker-us-west-1-#>
If you’d like to learn more about how we’re creating a csv file, you can check out the pandas documentation. Above, we are just concatenating x and y data sets as columns of data (axis=1) and converting that pandas dataframe into a csv file using .to_csv.
Boston Housing Data
For our very first time using SageMaker we will be looking at the problem of estimating the median cost of a house in the Boston area using the Boston Housing Dataset.
We will be using this dataset often throughout this module as it provides a great example on which to try out all of SageMaker’s features.
In addition, we will be using a random tree model. In particular, we will be using the XGBoost algorithm. The details of XGBoost are beyond the scope of this module as we are interested in learning about SageMaker. If you would like to learn more about XGBoost I would recommend starting with the documentation which you can find at https://xgboost.readthedocs.io/en/latest/
The notebook we will be working though in this video and in the following two videos can be found in the Tutorial directory and is called Boston Housing - XGBoost (Batch Transform) - High Level.ipynb. Now that you know why Boston Housing and XGBoost are in the name, let’s talk a bit about the rest of it.
First, Batch Transform is the method we will be using to test our model once we have trained it. This is something that we will discuss a little more later on.
Second, High Level describes the API we will be using to get SageMaker to perform various machine learning tasks. In particular, it refers to the Python SDK whose documentation can be found here: https://sagemaker.readthedocs.io/en/latest/. This high level approach simplifies a lot of the details when working with SageMaker and can be very useful.
XGBoost in Competition
There’s a list of winning XGBoost-based solutions to a variety of competitions, at the linked XGBoost repository.
Estimators
You can read the documentation on estimators for more information about this object. Essentially, the Estimator is an object that specifies some details about how a model will be trained. It gives you the ability to create and deploy a model.
Training Jobs
A training job is used to train a specific estimator.
When you request a training job to be executed you need to provide a few items:
- A location on S3 where your training (and possibly validation) data is stored,
- A location on S3 where the resulting model will be stored (this data is called the model artifacts),
- A location of a docker container (certainly this is the case if using a built in algorithm) to be used for training
- A description of the compute instance that should be used.
Once you provide all of this information, SageMaker will executed the necessary instance (CPU or GPU), load up the necessary docker container and execute it, passing in the location of the training data. Then when the container has finished training the model, the model artifacts are packaged up and stored on S3.
You can see a high-level (which we’ve just walked through) example of training a KMeans estimator, in this documentation. This high-level example defines a KMeans estimator, and uses .fit() to train that model. Later, we’ll show you a low-level model, in which you have to specify many more details about the training job.
Supporting Materials
SageMaker Questions
- What are the main components of a SageMaker model?
Your reflection (my answer)
Model containers s3 for data storage Model Artifacts Model Estimator instance for training model transformer for testing
Things to think about
In SageMaker, a model is a collection of information that describes how to perform inference. For the most part, this comprises two very important pieces.
The first is the container that holds the model inference functionality. For different types of models this code may be different but for simpler models and models provided by Amazon this is typically the same container that was used to train the model.
The second is the model artifacts. These are the pieces of data that were created during the training process. For example, if we were fitting a linear model then the coefficients that were fit would be saved as model artifacts.
Fitting Models
2. What happens when a model is fit using SageMaker?
Your reflection
It is used for training. Created output Model artifacts.
Things to think about
When a model is fit using SageMaker, the process is as follows.
First, a compute instance (basically a server somewhere) is started up with the properties that we specified.
Next, when the compute instance is ready, the code, in the form of a container, that is used to fit the model is loaded and executed. When this code is executed, it is provided access to the training (and possibly validation) data stored on S3.
Once the compute instance has finished fitting the model, the resulting model artifacts are stored on S3 and the compute instance is shut down.
Lesson 3: Deploying a Model in SageMaker
Deploying a Model in SageMaker
In this lesson, we’re going to take a look at how we can use a model that has been created in SageMaker. We will do this by first deploying our model. For us, this means using SageMaker’s functionality to create an endpoint that will be used as a way to send data to our model.
Recall, from the first lesson in this section, that an endpoint is basically a way to allow a model and an application to communicate. An application, such as a web app, will be responsible for accepting user input data, and through an endpoint we can send that data to our model, which will produce predictions that can be sent back to our application!
For our purposes an endpoint is just a URL. Instead of returning a web page, like a typical url, this endpoint URL returns the results of performing inference. In addition, we are able to send data to this URL so that our model knows what to perform inference on. We won’t go too far into the details of how this is all set up since SageMaker does most of the heavy lifting for us.
An important aspect that we will encounter is that SageMaker endpoints are secured. In this case, that means that only other AWS services with permission to access SageMaker endpoints can do so.
To start with, we won’t need to worry about this too much since we will be working inside of a SageMaker notebook and so we will be able to access our deployed endpoints easily.
Later on we will talk about how to set things up so that a simple web app, which doesn’t need to be given special permission, can access our SageMaker endpoint.
Boston Housing Example
Now that you’ve had some time to try and build models using SageMaker, we are going to learn how to deploy those models so that our models can be interacted with using an endpoint.
Inside of the Tutorials folder is the Boston Housing - XGBoost (Deploy) - High Level.ipynb notebook which we will be looking at in the video below.
Using the high level approach makes deploying a trained model pretty straightforward. All we need to do is call the deploy method and SageMaker takes care of the rest.
Similarly, sending data to the deployed endpoint and capturing the resulting inference is easy too as SageMaker wraps everything up into the predict method, provided we make sure that our data is serialized correctly. In our case, serializing means converting the data structure we wish to send to our endpoint into a string, something that can be transferred using HTTP.
In the next video we’ll take a more in-depth look at how our model is being deployed.
WARNING – SHUT DOWN YOUR DEPLOYED ENDPOINT
Sorry for the yelling, but this is pretty important. The cost of a deployed endpoint is based on the length of time that it is running. This means that if you aren’t using an endpoint you really need to shut it down.
Deploying and Using a Sentiment Analysis Model
You’ve learned how to create and train models in SageMaker and how you can deploy them. In this example we are going to look at how we can make use of a deployed model in a simple web app.
In order for our simple web app to interact with the deployed model we are going to have to solve a couple problems.
The first obstacle is something that has been mentioned earlier.
The endpoint that is created when we deploy a model using SageMaker is secured, meaning that only entities that are authenticated with AWS can send or receive data from the deployed model. This is a problem since authenticating for the purposes of a simple web app is a bit more work than we’d like.
So we will need to find a way to work around this.
The second obstacle is that our deployed model expects us to send it a review after it has been processed. That is, it assumes we have already tokenized the review and then created a bag of words encoding. However, we want our user to be able to type any review into our web app.
We will also see how we can overcome this.
To solve these issues we are going to need to use some additional Amazon services. In particular, we are going to look at Amazon Lambda and API Gateway.
In the mean time, I would encourage you to take a look at the IMDB Sentiment Analysis - XGBoost - Web App.ipynb notebook in the Tutorials folder. In the coming videos we will go through this notebook in detail, however, each of the steps involved is pretty well documented in the notebook itself.
Text Processing
I mentioned that one of our tasks will be to convert any user input text into data that our deployed model can see as input. You’ve seen a few examples of text pre-processing and the steps usually go something like this:
- Get rid of any special characters like punctuation
- Convert all text to lowercase and split into individual words
- Create a vocabulary that assigns each unique word a numerical value or converts words into a vector of numbers
This last step is often called word tokenization or vectorization.
And in the next example, you’ll see exactly how I do these processing steps; I’ll also be vectorizing words using a method called bag of words. If you’d like to learn more about bag of words, please check out the video below, recorded by another of our instructors, Arpan!
Bag of Words
You can read more about the bag of words model, and its applications, on this page. It’s a useful way to represent words based on their frequency of occurrence in a text.
Creating and Using Endpoints
You’ve just learned a lot about how to use SageMaker to deploy a model and perform inference on some data. Now is a good time to review some of the key steps that we’ve covered. You have experience processing data and creating estimators/models, so I’ll focus on what you’ve learned about endpoints.
An endpoint, in this case, is a URL that allows an application and a model to speak to one another.

Endpoint steps
- You can start an endpoint by calling
.deploy()on an estimator and passing in some information about the instance.
xgb_predictor = xgb.deploy(initial_instance_count = 1, instance_type = 'ml.m4.xlarge')
- Then, you need to tell your endpoint, what type of data it expects to see as input (like .csv).
from sagemaker.predictor import csv_serializer
xgb_predictor.content_type = 'text/csv'
xgb_predictor.serializer = csv_serializer
- Then, perform inference; you can pass some data as the “Body” of a message, to an endpoint and get a response back!
response = runtime.invoke_endpoint(EndpointName = xgb_predictor.endpoint, # The name of the endpoint we created
ContentType = 'text/csv', # The data format that is expected
Body = ','.join([str(val) for val in test_bow]).encode('utf-8'))
- The inference data is stored in the “Body” of the response, and can be retrieved:
response = response['Body'].read().decode('utf-8') print(response) - Finally, do not forget to shut down your endpoint when you are done using it.
xgb_predictor.delete_endpoint()
Lesson 4 : Hyperparameter tuning
Introduction to Hyperparameter Tuning
Let’s take a look at how we can use SageMaker to improve our Boston housing model. To begin with, we will remind ourselves how we train a model using SageMaker.
Essentially, tuning a model means training a bunch of models, each with different hyperparameters, and then choosing the best performing model. Of course, we still need to describe two different aspects of hyperparameter tuning:
1) What is a bunch of models? In other words, how many different models should we train?
2) Which model is the best model? In other words, what sort of metric should we use in order to distinguish how well one model performs relative to another.
Boston Housing In-Depth
Now we will look at creating a hyperparameter tuning job using the low level approach. Just like in the other low level approaches, this method requires us to describe the various properties that our hyperparameter tuning job should have.
To follow along, open up the Boston Housing - XGBoost (Hyperparameter Tuning) - Low Level.ipynb notebook in the Tutorials folder.
Creating a hyperparameter tuning job using the low level approach requires us to describe two different things.
The first, is a training job that will be used as the base job for the hyperparameter tuning task. This training job description is almost exactly the same as the standard training job description except that instead of specifying HyperParameters we specify StaticHyperParameters. That is, the hyperparameters that we do not want to change in the various iterations.
The second thing we need to describe is the tuning job itself. This description includes the different ranges of hyperparameters that we do want SageMaker to vary, in addition to the total number of jobs we want to have created and how to determine which model is best.
Lesson 5: Updating a model
In this lesson we are going to take a look at updating an existing endpoint so that it conforms to a different endpoint configuration. There are many reasons for wanting to do this, the two that we will look at are, performing an A/B test and updating a model which is no longer performing as well.
To start, we will look at performing an A/B test between two different models. Then, once we’ve decided on a model to use, updating the existing endpoint so that it only sends data to a single model.
For the second example, it may be the case that once we’ve built a model and begun using it, the assumptions on which our model is built begin to change.
For instance, in the sentiment analysis examples that we’ve looked at our models are based on a vocabulary consisting of the 5000 most frequently appearing words in the training set. But what happens if, over time, the usage of words changes? Then our model may not be as accurate.
When this happens we may need to modify our model, often this means re-training it. When we do, we’d like to update the existing endpoint without having to shut it down. Fortunately, SageMaker allows us to do this in a straightforward way.
SageMaker Retrospective
In this module we looked at various features offered by Amazon’s SageMaker service. These features include the following.
- Notebook Instances provide a convenient place to process and explore data in addition to making it very easy to interact with the rest of SageMaker’s features.
- Training Jobs allow us to create model artifacts by fitting various machine learning models to data.
- Hyperparameter Tuning allow us to create multiple training jobs each with different hyperparameters in order to find the hyperparameters that work best for a given problem.
- Models are essentially a combination of model artifacts formed during a training job and an associated docker container (code) that is used to perform inference.
- Endpoint Configurations act as blueprints for endpoints. They describe what sort of resources should be used when an endpoint is constructed along with which models should be used and, if multiple models are to be used, how the incoming data should be split up among the various models.
- Endpoints are the actual HTTP URLs that are created by SageMaker and which have properties specified by their associated endpoint configurations. Have you shut down your endpoints?
- Batch Transform is the method by which you can perform inference on a whole bunch of data at once. In contrast, setting up an endpoint allows you to perform inference on small amounts of data by sending it do the endpoint bit by bit.
In addition to the features provided by SageMaker we used three other Amazon services.
In particular, we used S3 as a central repository in which to store our data. This included test / training / validation data as well as model artifacts that we created during training.
We also looked at how we could combine a deployed SageMaker endpoint with Lambda and API Gateway to create our own simple web app.NEXT
SageMaker Documentation
- Developer Documentation can be found here: https://docs.aws.amazon.com/sagemaker/latest/dg/
- Python SDK Documentation (also known as the high level approach) can be found here: https://sagemaker.readthedocs.io/en/latest/
- Python SDK Code can be found on github here: https://github.com/aws/sagemaker-python-sdk
A. AWS Service Utilization Quota (Limits)
You need to understand the way AWS imposes utilization quotas (limits) on almost all of its services. Quotas, also referred to as limits, are the maximum number of resources of a particular service that you can create in your AWS account.
- AWS provides default quotas, for each AWS service.
- Importantly, each quota is region-specific.
- There are three ways to view your quotas, as mentioned here:
- Service Endpoints and Quotas,
- Service Quotas console, and
- AWS CLI commands –
list-service-quotasandlist-aws-default-service-quotas
- In general, there are three ways to increase the quotas:
- Using Amazon Service Quotas service – This service consolidates your account-specific values for quotas across all AWS services for improved manageability. Service Quotas is available at no additional charge. You can directly try logging into Service Quotas console here.
- Using AWS Support Center – You can create a case for support from AWS.
- AWS CLI commands –
request-service-quota-increase
A.1. Amazon SageMaker Utilization Quota (Limits)
You can view the Amazon SageMaker Service Limits at “Amazon SageMaker Endpoints and Quotas” page. You can request to increase the AWS Sagemaker quota using the AWS Support Center only. Note that currently the Amazon Service Quotas does not support SageMaker service. However, SageMaker would be introduced soon into Service Quotas. AWS is moving to make users manage quotas for all AWS services from one central location.

Sagemaker would be introduced soon into Services Quota – Courtesy – Amazon Service Quotas
A.2. Increase Sagemaker Instance Quota (Limit) using AWS Support Center
Read the note and recommendation below before proceeding further.
Note
Suppose a student has a quota of 20 instances of ml.m4.xlarge by default, they would not notice it unless they run the notebook that uses that instance. Now, if they go to the AWS Support Center, to request a service limit increase by 1, their instance limit will be degraded from 20 to 1.
Recommendation
- For
ml.m4.xlarge– The default quota would be any number in the range [0 – 20]. Students can expect an error – ‘ResourceLimitExceeded’, when executing the notebook in the concept Boston Housing Problem – Training The Model, later in this lesson. In such a case only, the student must request a limit increase forml.m4.xlarge. - For
ml.p2.xlarge– The default quota would be either 0 or 1, therefore it is alright to go ahead and request an increase anytime.
Let’s look at the steps to increase the Sagemaker instance quota (limit) using AWS Support Center.
- Sign in to AWS console – https://aws.amazon.com/console/
Sign in to AWS console
- Go to the AWS Support Center and create a case.

AWS Support Center
- Click on Service limit increase

Create a case for support
- It will expand three sections – Case details, Case description, and Contact options on the same page. In Case details section, select “Sagemaker” as the Limit type.

The Case details section asking you the Limit type
- It will expand one more section – Requests on the same page. In Request section, and select the Region in which you are using the SageMaker service.
- Select Sagemaker Training as the Resource Type
- Select the instance type (ml.m4.xlarge or ml.p2.xlarge) under the Limit field
- Under new limit value, select 1

Request section that takes Region, Resource type, and LImit values
- Provide a case description and the contact options before submitting the case to support.
Note: The AWS UI is subject to change on a regular basis. We advise students to refer to the AWS documentation for any updated step/UI.
4 Machine Learning use cases
Lesson 1: Population Segmentation
Course Outline
Throughout this course, we’ll be focusing on deployment tools and the machine learning workflow; answering a few big questions along the way:
- How do you decide on the correct machine learning algorithm for a given task?
- How can we utilize cloud ML services in SageMaker to work with interesting datasets or improve our algorithms?
To approach these questions, we’ll go over a number of real-world case studies, and go from task and problem formulation to deploying models in SageMaker. We’ll also utilize a number of SageMaker’s built-in algorithms.
Case Studies
Case studies are in-depth examinations of specific, real-world tasks. In our case, we’ll focus on three different problems and look at how they can be solved using various machine learning strategies. The case studies are as follows:
Case Study 1 – Population Segmentation using SageMaker
You’ll look at a portion of US census data and, using a combination of unsupervised learning methods, extract meaningful components from that data and group regions by similar census-recorded characteristics. This case study will be a deep dive into Principal Components Analysis (PCA) and K-Means clustering methods, and the end result will be groupings that are used to inform things like localized marketing campaigns and voter campaign strategies.
Case Study 2 – Detecting Credit Card Fraud
This case will demonstrate how to use supervised learning techniques, specifically SageMaker’s LinearLearner, for fraud detection. The payment transaction dataset we’ll work with is unbalanced, with many more examples of valid transactions vs. fraudulent, and so you will investigate methods for compensating for this imbalance and tuning your model to improve its performance according to a specific product goal.
Custom Models – Non-Linear Classification
Adding on to what you have learned in the credit card fraud case study, you will learn how to manage cases where classes of data are not separable by a linear line. You’ll train and deploy a custom, PyTorch neural network for classifying data.
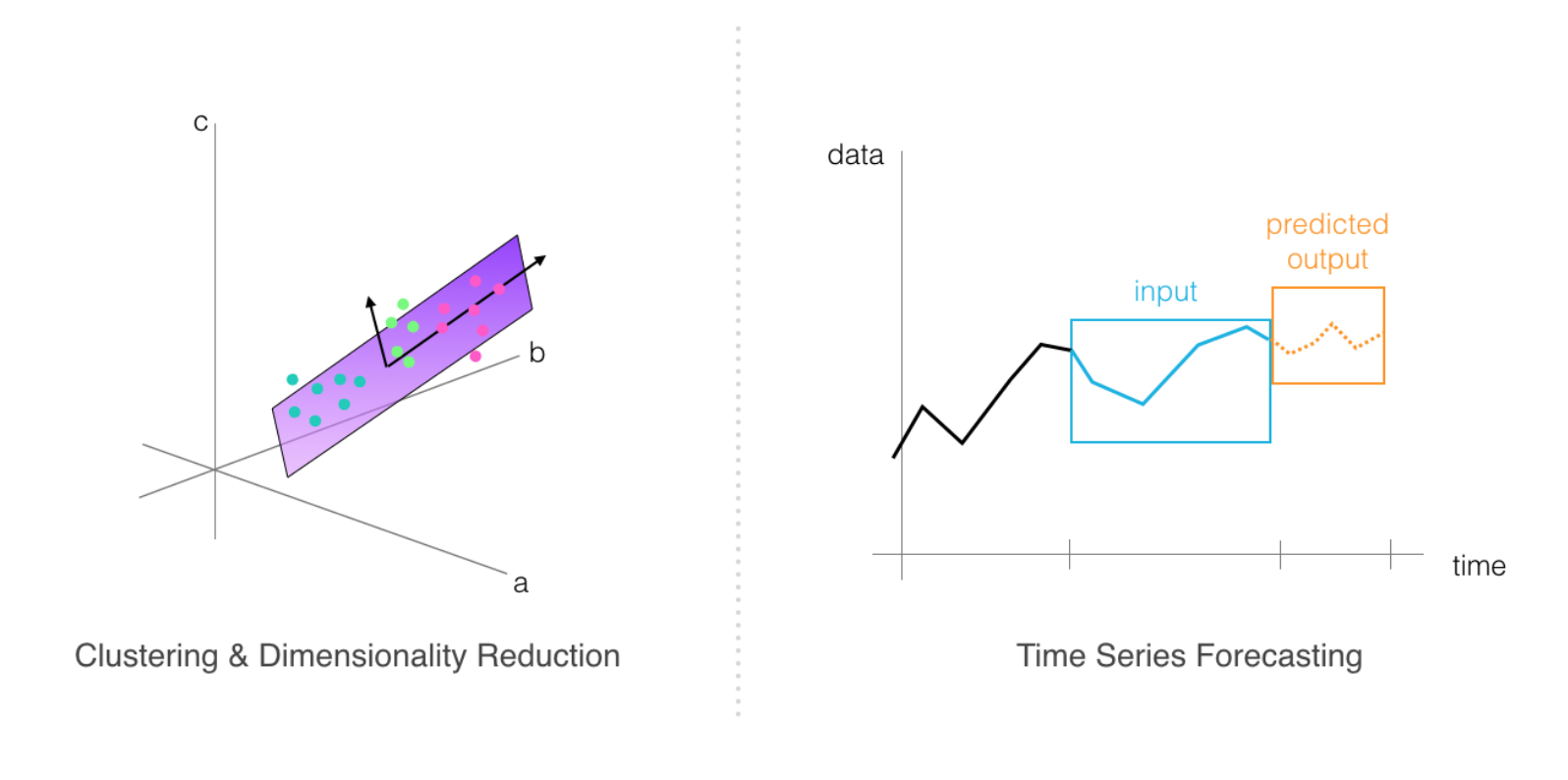
Case Study 3 – Time-Series Forecasting
This case demonstrates how to train SageMaker’s DeepAR model for forecasting predictions over time. Time-series forecasting is an active area of research because a good forecasting algorithm often takes in a number of different features and accounts for seasonal or repetitive patterns. In this study, you will learn a bit about creating features out of time series data and formatting it for training.
Project: Plagiarism Detection
You’ll apply the skills that you’ve learned to a final project; building and deploying a plagiarism classification model. This project will test your ability to do [text] data processing and feature extraction, your ability to train and evaluate models according to an accuracy specification, and your ability to deploy a trained model to an endpoint.
By the end of this course, you should have all the skills you need to build, train and deploy models to solve tasks of your own design!
K-Means Clustering
To perform population segmentation, one of our strategies will be to use k-means clustering to group data into similar clusters. To review, the k-means clustering algorithm can be broken down into a few steps; the following steps assume that you have n-dimensional data, which is to say, data with a discrete number of features associated with it. In the case of housing price data, these features include traits like house size, location, etc. features are just measurable components of a data point. K-means works as follows:
You select k, a predetermined number of clusters that you want to form. Then k points (centroids for k clusters) are selected at random locations in feature space. For each point in your training dataset:
- You find the centroid that the point is closest to
- And assign that point to that cluster
- Then, for each cluster centroid, you move that point such that it is in the center of all the points that are were assigned to that cluster in step 2.
- Repeat steps 2 and 3 until you’ve either reached convergence and points no longer change cluster membership _or_ until some specified number of iterations have been reached.
This algorithm can be applied to any kind of unlabelled data. You can watch a video explanation of the k-means algorithm, as applied to color image segmentation, below. In this case, the k-means algorithm looks at R, G, and B values as features, and uses those features to cluster individual pixels in an image!
Color Image Segmentation
Data Dimensionality
One thing to note is that it’s often easiest to form clusters when you have low-dimensional data. For example, it can be difficult, and often noisy, to get good clusters from data that has over 100 features. In high-dimensional cases, there is often a dimensionality reduction step that takes place before data is analyzed by a clustering algorithm. We’ll discuss PCA as a dimensionality reduction technique in the practical code example, later.
PCA
Principal Component Analysis (PCA) attempts to reduce the number of features within a dataset while retaining the “principal components”, which are defined as weighted combinations of existing features that:
- Are uncorrelated with one another, so you can treat them as independent features, and
- Account for the largest possible variability in the data!
So, depending on how many components we want to produce, the first one will be responsible for the largest variability on our data and the second component for the second-most variability, and so on. Which is exactly what we want to have for clustering purposes!
PCA is commonly used when you have data with many many features.
You can learn more about the details of the PCA algorithm in the video, below.
Now, in our case, we have data that has 34-dimensions and we’ll want to use PCA to find combinations of features that produce the most variability in the population dataset.
The idea is that components that cause a larger variance will help us to better differentiate between data points and (therefore) better separate data into clusters.
So, next, I’ll go over how to use SageMaker’s built-in PCA model to analyze our data.
